- Addition
- Scalar multiplication
Linear Combinations (c, d, e ):
- cu + dv
- cu + dv + ew
Properties of Dot Product:
- Distributive:
- Non-Associative:
- Commutative:
Cosine Formula for Dot Product: (note: cos(θ) = 0 when θ = 90°)
Length of a vector:
Matrix operations:
- Addition (both matrices should have the same dimensions)
- Scalar multiplication
- Transpose: mapping A ∈ to B ∈ with
- Trace: sum of all the elements along the diagonal
- Matrix multiplication (reminder: A∈ and B∈ then C=AB∈)
Multiplication Properties:
- Distributivity: and
- Associativity:
- Non-commutative: (because of dimensions)
- Multiplication with the identity matrix results in the matrix itself
Properties of Transpose:
- and
Symmetric Matrices:
- if is symmetric
Systems of Linear Equations Recap:
- Gaussian Elimination
- Row Echelon/Reduced Row Echelon Form
A matrix is in row echelon form if
- all rows having only zero entries are at the bottom
- The pivot (the leftmost non-zero entry) of every non-zero row, called the pivot, is to the right of the leading entry of every row above
A matrix is in reduced row echelon form if:
- it is in row echelon form
- the leading entry in each nonzero row is 1 (called a leading one)
- each column containing a leading 1 has zeros in all its other entries (or in other words, above the pivot if condition one is achieved)
Properties of Determinants:
- Matrix must be square
- The determinant of the identity matrix is 1.
- The exchange of two rows multiplies the determinant by −1.
- Multiplying a row or a column by a number multiplies the determinant by this number.
- Adding a multiple of one row to another row does not change the determinant.
- If two rows of matrix A are equal, then .
- A matrix with a row of zeros has .
- If A is triangular then is the product of diagonal entries.
NOTE
For a deep dive into geometric interpretations and ML applications, see 5. Determinants.
Laplace Expansion Example:
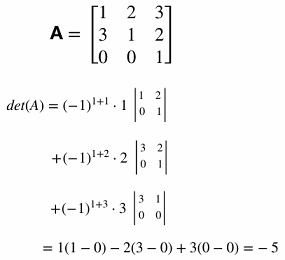
Invertibility:
- Matrix must be square
- If A is singular, then . If A is invertible, then .
- Can calculate the inverse using Gaussian Elimination
- →
- Inverse for a 2x2:
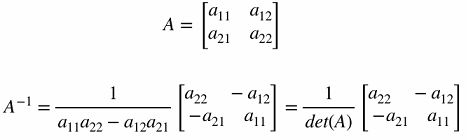
Vector Spaces and Subspaces
A subspace is defined as a set of all vectors that can be created by taking linear combinations of some vectors or a set of vectors.
Formally, a subspace is the set of all vectors that satisfy the following conditions:
- Must be closed under addition and multiplication
- Must contain the zero vector
Note
A vector space needs to contain all linear combinations of its vectors.
Example 1: Possible subspaces
| Dimension | Subspaces in : | Subspaces in : |
|---|---|---|
| 0 | The zero vector | The zero vector |
| 1 | Lines that pass through the origin | Lines that pass through the origin |
| 2 | All of | Planes that pass through the origin |
| 3 | - | All of |
Dimension of a subspace
The dimension of a subspace is always ≤ the dimension of the space it lives in.
Example 2: What does NOT qualify as a subspace? Think about a line that doesn’t pass through the origin - say, all points where . If we pick a vector on that line, like (0, 1), and we multiply it by the scalar 0, we get (0, 0) - which is NOT on the line . So that line isn’t closed under scalar multiplication, and therefore can’t be a subspace.
The distinction:
- While is contained in ℝ² (every point on the line is in ℝ² - (0,1), (1,2), (2,3) etc.)
- It is NOT a subspace of ℝ² (doesn’t contain zero vector, not closed under operations)
- Therefore, it does not qualify as (does not form) a subspace.
The four fundamental subspaces of
| Name | Dim | Note |
|---|---|---|
| Column Space | C(A)∈ | Pivot columns of the original matrix |
| Null Space | N(A)∈ | - Solve , set free column variables to 1 respectively - # of free columns = dimension of null space |
| Row Space | C()∈ | Pivot rows |
| Left Null Space | N()∈ | Solve for y where |
Dimensions For matrix A with dimensions x:
- (# of columns)
- (# of rows)
- Also,
Orthogonal Subspaces
If the null space is {(0,0,0)} then (only consists of the zero vector),
- Dimension of null space = 0
- Number of free columns = 0
- All columns are pivot columns
Null space of A
If vector is in the null space of matrix A, then A.
Complete Solution System of Linear Equations : Set all free variables to 0, then solve (or where R is the echelon/reduced echelon form)
: Set free columns to 1 and solve . If there are more than one, set them respectively. For example, if there are two free variables (let’s say and ) first set , and solve for . Then set , and solve for . Two free variables mean there will be two special solutions.
A system’s solution set has three possibilities:
- unique solution
- infinite solutions
- no solution
If the system has either,
- no solution OR
- infinitely many solutions
Rank
- Matrix rank = # of pivots
- In a square matrix, if the rank < # of columns that means there are linearly dependent rows, thus the matrix is not invertible ()
- The rank of A = # of independent rows = # of independent columns (very important)
Basis
> $$ \begin{aligned} \begin{bmatrix} 1 && 1 && 1 \\ 1 && 1 && 2 \\ 0 && 7 && 0 \end{bmatrix} \end{aligned}Tip for Finding the Span
If we want to find that in the span of $$ \begin{aligned} S = {\begin{bmatrix} 1 \ 1 \ 0 \end{bmatrix}, \begin{bmatrix} 1 \ 1 \ 7 \end{bmatrix}} \end{aligned}
If the rank is smaller than the number of columns, can be expressed as a linear combination of the other vectors. In this case, the rank is <3 so yes, is in the span of S.
Why use different bases?
- Simplification: Some problems become way easier in a different basis
- Example: In physics, choosing a basis aligned with forces makes calculations simpler
- Natural coordinates: Sometimes a problem has a natural coordinate system
- Example: If you’re studying oscillations, sine and cosine functions form a natural basis
- Revealing structure: Different bases can reveal hidden patterns in data
- Example: Principal Component Analysis (PCA) in data science finds a basis that shows the most important directions in your data
Changing Basis
Solve for where the basis A, B and is known: You get represented in basis B.
Orthogonality
- Two vectors are orthogonal if their dot product is 0.
- Two subspaces and of a vector space are orthogonal if every vector in is perpendicular to every vector in .
- The null space and the row space are orthogonal subspaces of .
- The left null space and the column space are orthogonal subspaces of .
Projections
The projection of onto a subspace is the closest vector in . A projection matrix is a symmetric matrix with . The projection of is is given by .
Projection onto a line
- x is a scalar.
Projection onto a Subspace
- x is a scalar.
Theorem: If has linearly independent columns then is invertible.
Least Squares Approximation
- Solve where
and
Orthonormal Vectors
Vectors are orthonormal if
- 0 when
- 1 when
Assume A has orthonormal column, then we can find the projection matrix using
Gram-Schmidt Process

Eigenvectors & Eigenvalues
If, then is an eigenvector of A with eigenvalue . In other words, lies in the same one-dimensional subspace as .
Finding eigenvectors:
should have a non-trivial null space. Which means it is singular and .
Diagonalization
where is the diagonal eigenvalue matrix and is the eigenvector matrix.
Spectral Theorem
For a symmetric matrix , the following diagonalization can be written:
where is the orthonormal eigenvector matrix. i.e. eigenvectors of a real symmetric matrix are always perpendicular.
Singular Value Decomposition
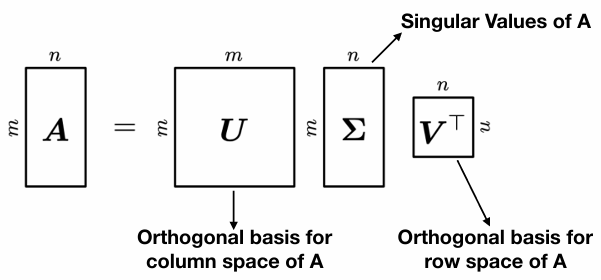
Tip: SVD can be used for dimensionality reduction or compression.
or,
Once you find and , find by calculating where and are eigenvectors of and . is the square root of eigenvalues obtained from .
Important note: and should have unit eigenvectors. Also, sort eigenvectors in descending order of corresponding eigenvalues.