A fixed-window neural language model
Improvements over n-gram
- No sparsity problem
- Model size is not
Remaining problems:
- Fixed window is too small
- Enlarging window enlarges W (weight vector)
- Window can never be large enough!
- Each x(i) uses different rows of W. We don’t share weights across window.
Solution: Recurrent Neural Networks (RNN)
RNN: a function that compresses everything seen so far into a vector.
RNNs:
- Take sequential input of any length
- Apply the same weights on each step
- Can optionally produce output on each step
Can be used for:
- part-of-speech tagging
- classification
- translation
- summarization
- speech recognition
- they can also be used to generate text
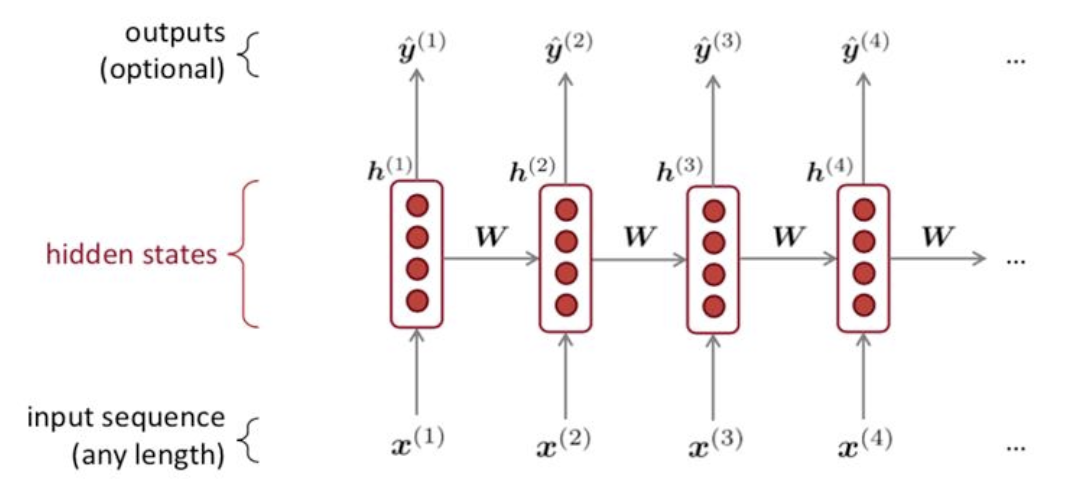
Advantages:
- Can process any length input
- Model size doesn’t increase for longer input
- Computation for step t can use information from many steps back (in theory)
- Weights are shared across time stamps: representation are shared
Disadvantages:
- Recurrent computation is slow
- In practice, difficult to access information from multiple steps back
Different Architectures
- one-to-one
- one-to-many
- many-to-one
- many-to-many
Effect of vanishing gradient on RNN-LM
LM task: When she tried to print her tickets, she found that the printer was out of toner. She went to the stationery store to buy more toner. It was very overpriced. After installing the toner into the printer, she finally printed her [blank].
To learn from this training example, the RNN-LM needs to model the dependency between “tickets” on the 7th step and the target word “tickets” at the end. But if gradient is small, the model can’t learn this dependency. So the model is unable to predict similar long-distance dependencies at test time.
- Syntactic recency: The writer of the books is (correct)
- Sequential recency: The writer of the books are (incorrect)
Due to vanishing gradient, RNN-LMs are better at learning from sequential recency than syntactic recency, so they make this type of error more often than we’d like [Linzen et al 2016]
Long Short-Term Memory (LSTM)
A type of RNN proposed by Hochreiter and Schmidhuber in 1997 as a solution to the vanishing gradients problem.
Gated Recurrent Networks (GRU)
Researchers have proposed many gated RNN variants, but LSTM and GRU are the most widely-used.
- The biggest difference is that GRU is quicker to compute and has fewer parameters.
- There is no conclusive evidence that one consistently performs better than the other.
- LSTM is a good default choice (especially if your data has particularly long dependencies, or you have lots of training data).
- Rule of thumb: start with LSTM, but switch to GRU if you want something more efficient.
Bi-directional RNNs
Previous versions of RNNs can capture the left context, what about the right? Example: “The movie was terribly exciting”
Solution: Have 2 RNNs, Forward RNN and Backward RNN, then concatenate hidden states.
Key Features:
- Bi-directional RNNs are only applicable if you have access to the entire input sequence. They are not applicable to Language Modeling, because in LM you only have left context available.
- If you do have entire input sequence (e.g. any kind of encoding), bidirectionality is powerful (you should use it by default).
- For example, BERT (Bidirectional Encoder Representations from Transformers) is a powerful pretrained contextual representation system built on bidirectionality.
Multi-layered RNNs
These are also powerful options.
CNNs for Text
Properties:
- Some patterns are much smaller than the whole image
- The same patterns appear in different regions.
- Subsampling the pixels will not change the object
Why might CNN work for text?
- Recurrent neural nets cannot capture phrases without prefix context
- Often capture too much of last words in final vector
Application: Translation - Recurrent Continuous Translation Models - ACL Anthology
Reading: CNNs for Text Classification – Cezanne Camacho – Machine and deep learning educator.