In-memory semantic knowledge graph that converts personal documents into topic-aware discovery, visualizations, and reproducible experiment logs.
Quick Facts
- Context: CS584 NLP Knowledge Graph Project
- Tech Stack: Python 3.13+, sentence-transformers (mpnet), KeyBERT, TextRank, NumPy, uv
- Links: GitHub Repo | Project Report (PDF)
Overview and Problem
The project builds a lightweight knowledge graph from local documents to improve semantic search and topic discovery. It aims to evaluate different tag extraction strategies and similarity thresholds for optimal graph connectivity.
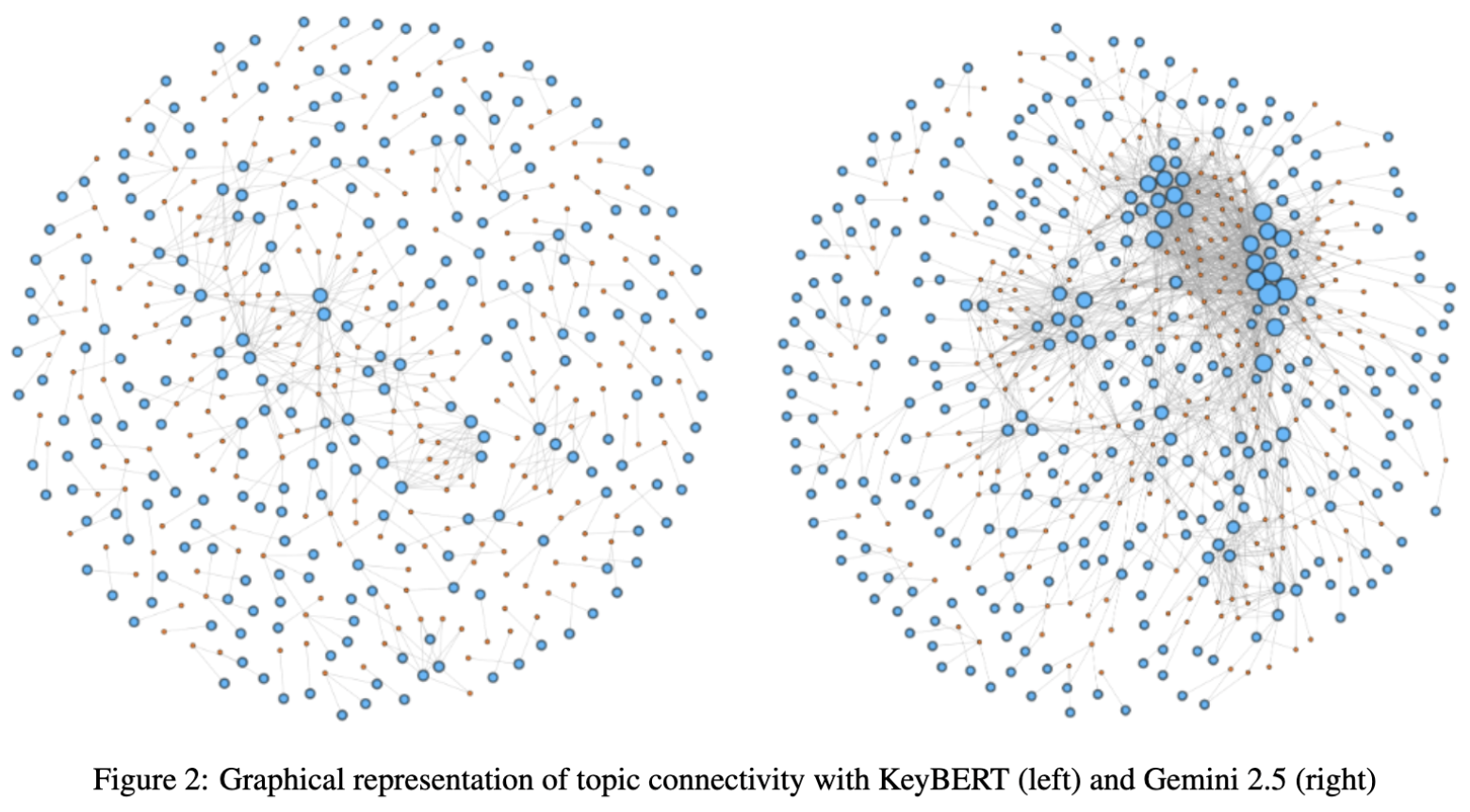
What I Built
- Engineered an automated pipeline to extract semantic tags using LLM-backed generation with statistical fallbacks (KeyBERT, TextRank).
- Implemented embeddings using sentence-transformers (mpnet models) to map tags into semantic space.
- Designed a cosine matching algorithm with configurable k and threshold parameters to link documents to topic centroids.
- Developed interactive HTML graph exports and structured text dumps for visualization and debugging.
Key Results and Impact
- Achieved best semantic coherence of 0.97 (LLM, k=3, threshold=0.7).
- Reached strongest connectivity with an LCC ratio of 1.00 (TextRank, k=5 or k=7, threshold=0.3).
- Handled dynamic topic counts ranging from 32 to 475 across thresholds, demonstrating a clear granularity tradeoff.
Core Learnings
- Balanced midpoints yielded coherence around 0.77–0.81 with LCC 0.50–0.57 at k=3, threshold=0.5 across different extractors, showing the trade-offs between precision and connectivity.
Related: Projects MOC