Linear Discriminant Analysis / Fisher’s Linear Discriminant
| Type |
|---|
| Linear Classifier |
Good Illustration: An illustrative introduction to Fisher’s Linear Discriminant - Thalles’ blog
Find an orientation along which the projected samples are well separated.
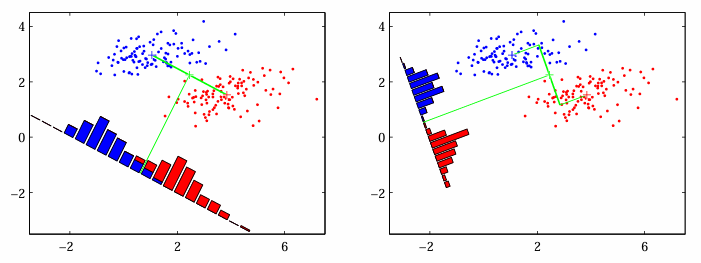
Fisher’s Linear Discriminant
- We want class means to be as far as possible. The denominator is the total within-class scatter of the projected samples.
where $s_+^2$ or $s_-^2$ is (almost like variance),
Define following matrices:
$S_+$ or $S_-$ takes the form
Using these we obtain,
$J$ is maximized when (take derivate with respect to w)
Notice:
- $w^TS_Ww$ and $w^TS_Bw$ are scalars, thus we get
- If we take $\lambda = \alpha / \beta$ we get $S_Bw=λS_Ww$ which the generalized eigenvalue problem:
From the generalized eigenvalue equation, we derive that the optimal $w$ is:
Yes but how?!
Notice $(m_+−m_−)^Tw$ in $S_Bw=(m_+−m_−)(m_+−m_−)^Tw$ is a scalar. That means the equation looks like $S_Bw=c.(m_+−m_−)$. This shows that $S_Bw$ is always proportional to $(m_+−m_−)$ regardless of what $w$ is! Plug this into the equation above to get the generalized eigenvalue equation.
To summarize, Fisher’s Discriminant,
- Gives the linear function with the maximum ratio of between-class scatter to within-class scatter
- The problem, e.g. classification, has been reduced from a d-dimensional problem to a more manageable one-dimensional problem.
- Can be extended to multiclass classification